
The hidden dependency no one talks about
Bank transaction categorisation doesn't sound like the kind of problem that keeps lenders up at night. But it should.
If your model thinks a Shopify Capital repayment is Shopify revenue, you've just overstated a business's income by tens of thousands of pounds. If a legitimate supplier payment gets tagged as debt, a healthy company looks overleveraged. These aren't edge cases. They're the routine reality of bank transaction data, and in lending, every downstream decision depends on getting the labels right.
What makes this particularly dangerous is that categorisation errors don't stay contained. A single mislabelled transaction feeds into revenue calculations, debt ratios, burn rate, and ultimately the credit score itself. The downstream models have no way of knowing their inputs are wrong. They just produce a confident answer based on bad data.
The industry's dirty secret
When we launched our cash-flow-based credit assessment framework in March 2025, a system that underwrites lending decisions from £10,000 to £500,000 using bank transaction and sales platform data alone (no financial statements required), we initially relied on established third-party categorisation providers.
When our underwriting team audited the output, the results were sobering. Roughly 25% of transactions were miscategorised. In the categories that matter most for credit decisions, particularly debt recognition, where the difference between a loan repayment and a revenue payment can swing a decision by six figures, accuracy dropped as low as 39%.
This isn't a problem unique to us. It's an industry-wide gap, and most lenders either don't measure it or have learned to live with it by layering manual review on top.
We decided not to live with it.
Why this problem is harder than it looks
Bank transaction descriptions are not clean data. They're truncated, inconsistent, full of merchant codes and reference numbers, and vary wildly between banks. "SHOPIFY CAPITAL" and "SHP*CAP" might mean the same thing. A transfer between a company's own accounts may look similar to a payment to a supplier.
Three specific challenges make this unusually difficult for ML.
First, the same merchant can appear in multiple categories depending on context. A payment to Amazon could be advertising spend, inventory purchasing, or even a loan repayment to Amazon Lending.
Second, many of the most important categories for lending (debt and investment in particular) are rare in any given dataset, which means the model has very few examples to learn from.
Third, directionality matters: revenue can only be a credit and advertising spend can only be a debit, but a general-purpose classifier has no way to enforce that constraint.
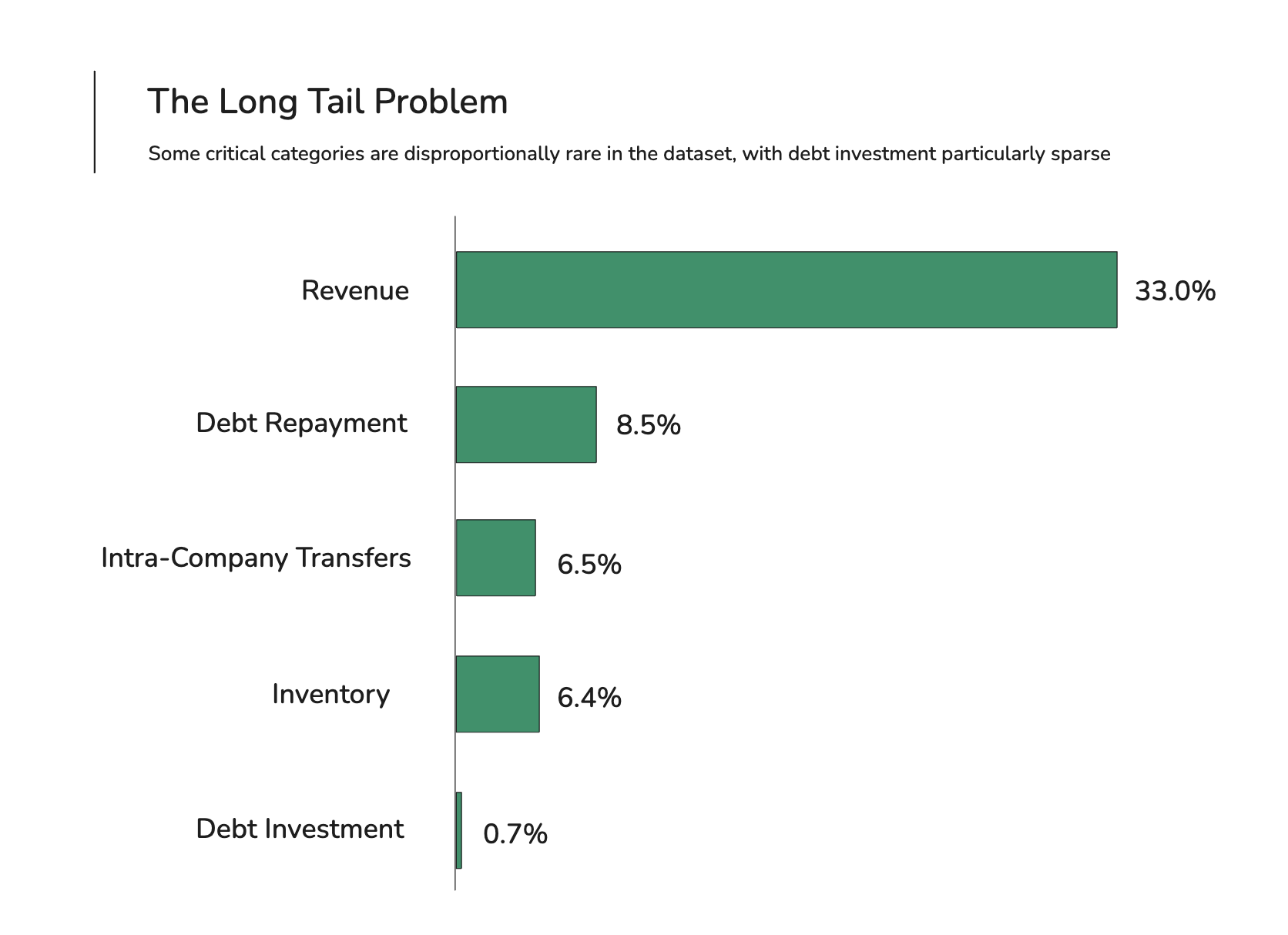
What changed: a purpose-built transformer trained on proprietary data
Two things made the difference.
The first was architectural: transformer models, the same family behind large language models, turned out to be exceptionally good at reading noisy transaction descriptions and extracting meaning from them. But we didn't need a model that generates text. We needed one that reads text and selects a category. So we built a compact transformer with a classification layer on top: roughly 30 million parameters, more than 10,000 times smaller than a frontier LLM. It classifies 10,000 transactions in under 7 seconds, fast enough to support real-time credit decisioning.
The second advantage was data. Over several years, our underwriting team manually reviewed and corrected millions of transactions. Every time an underwriter changed a category from "Revenue" to "Debt Repayment", or confirmed a correct label, that correction was stored. This created a proprietary training dataset that reflects the actual distribution and edge cases of lending decisions, not generic consumer spending.
We also built two structural innovations into the model.
Direction constraints zero out impossible category predictions. The model literally cannot predict "Revenue" for an outgoing payment, no matter how confident it is. This eliminated an entire class of errors at zero computational cost.
And for rare but critical categories, we merged direction-dependent categories during training (e.g. "ATM Cash Inflows" and "ATM Cash Outflows" become a single "ATM" class) and split them back at prediction time, giving the model more training examples without sacrificing accuracy.
On a held-out test set reflecting real customer distributions, the model achieved 97-99% accuracy on high-impact categories such as revenue, debt repayment, and tax, compared to approximately 39-90% from previous third-party providers.
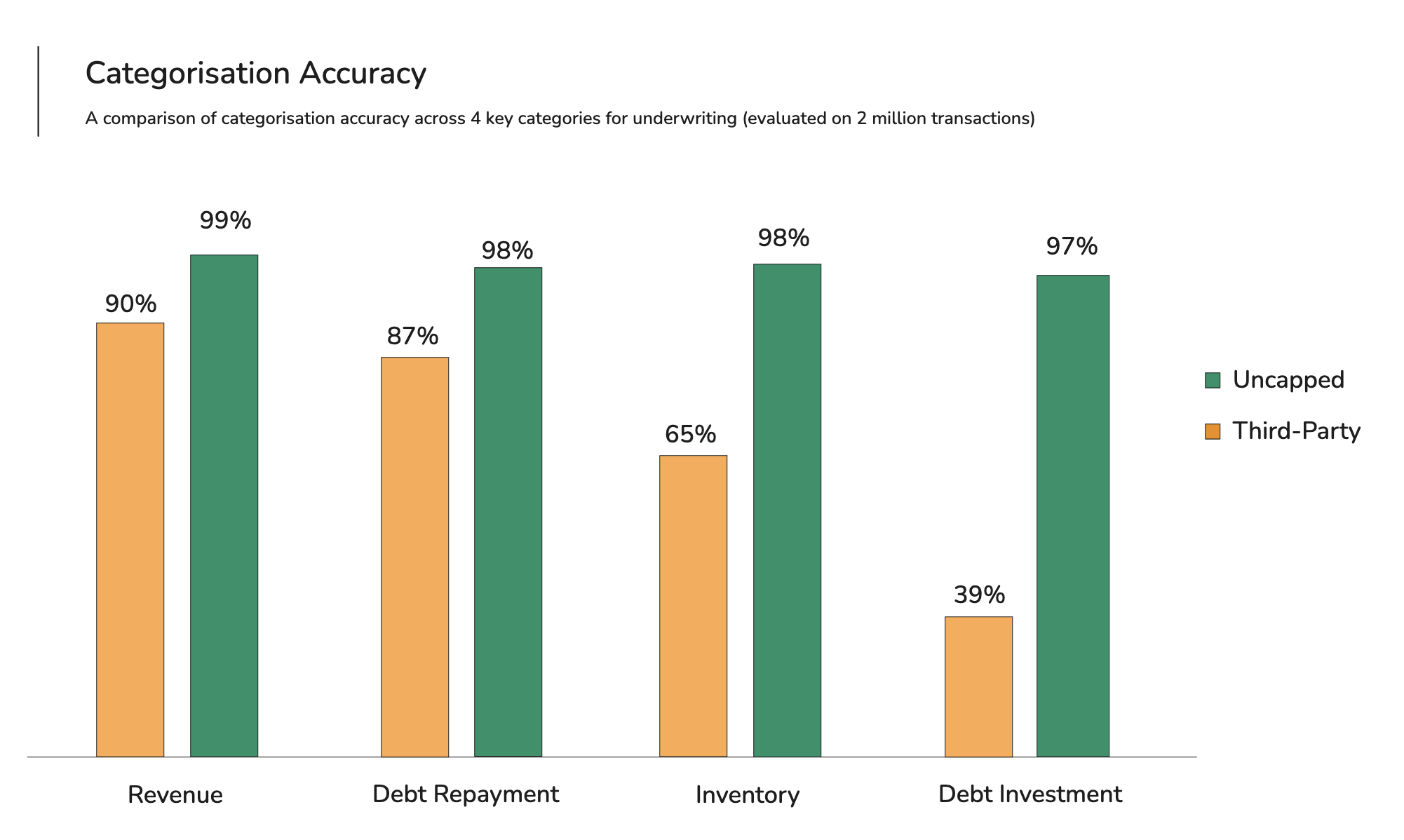
What changed when we shipped it
Better categorisation sounds like a backend improvement. In practice, it changed the experience for everyone involved: clients, underwriters, and the credit models sitting between them.
Before, a significant proportion of applications were referred to manual review because miscategorisation made the numbers look wrong. A business with healthy finances could get flagged because a loan drawdown was tagged as revenue (inflating income) or a legitimate payment was tagged as debt (inflating liabilities). An underwriter would identify the categorisation error, correct it, and approve the deal, a loop that could take hours. Now, because the model gets it right the first time, more applications flow straight through to automated decisioning.
The impact on offer quality is equally important. Our credit scorecards are only as good as the data feeding them. When debt and revenue recognition improves, the scorecards see a truer picture of each business. That means fewer good businesses turned away because phantom debt dragged their score down, and fewer undervalued offers because legitimate revenue was missed or misclassified.
For our underwriting team, the shift has been transformative. They used to spend a meaningful part of their day correcting transaction categories, effectively doing data cleaning before they could start the real analysis. With 99% accuracy in core categories, the volume of manual overrides has dropped substantially. Underwriters now spend their time on what they were hired for: assessing risk, structuring deals, and making judgment calls on the cases that genuinely need a human eye.
What this means for the industry
Transaction categorisation has been a bottleneck hiding in plain sight across alternative lending. Lenders have compensated with manual review, conservative underwriting buffers, and slower turnaround times, all of which increase cost and reduce access to capital for the businesses that need it most.
With recent advances in transformer architectures and sufficiently large proprietary datasets, fully automated, high-accuracy categorisation is now viable in practice. For Uncapped, it's the foundation that lets us underwrite a £300,000 loan to an Amazon seller in under four minutes and get the decision right. But the implications go beyond any single lender. As the industry moves toward real-time, data-driven credit decisions, the quality of transaction categorisation will increasingly separate the platforms that can scale from those that can't.
We're continuing to invest here. The model improves every month through a continuous learning pipeline fed by ongoing underwriter corrections, and we're expanding the category taxonomy as we enter new markets and product lines. The hard problem, it turns out, was always the right one to solve.
About Uncapped
Uncapped is a technology-driven lender providing working capital to e-commerce businesses across the UK, US, and Germany. Uncapped offers Term Loans, Lines of Credit, and Cash Advances to businesses on Amazon, Shopify, and other platforms, with loan sizes from £10,000 to £2,000,000.
For partnership enquiries: partnerships@weareuncapped.com

%20(1).jpg)